
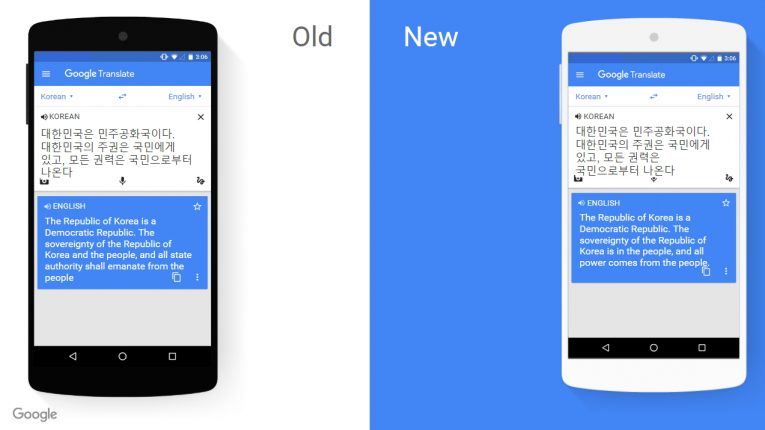
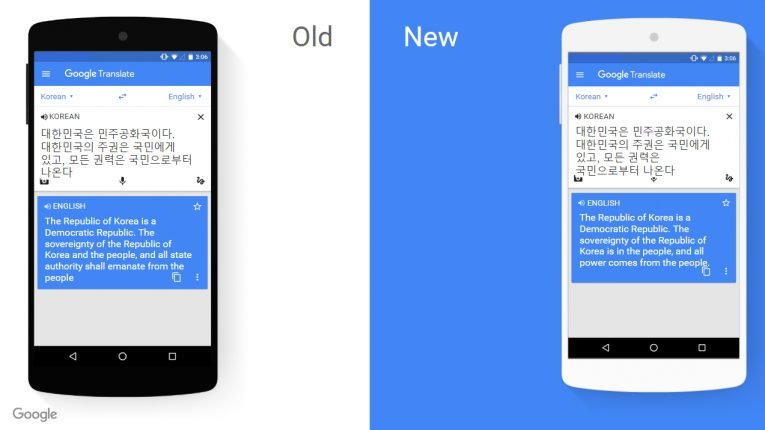
지난 2016년 11월 구글 번역기는 한국어를 포함해 8개의 언어 조합에 ‘구글 신경망 기계번역(GNMT)’이라는 새로운 기술을 적용했다.
이로 인해 구글 번역기의 번역 완성도와 정확도는 눈에 띄게 향상 됐다.
버락 투로프스키 구글 번역 프로덕트 매니지먼트 총괄이 영상 기자간담회에서 밝힌 구글 번역기와 관련된 흥미로운 사실을 모아봤다.
#1 번역 방법은 네이버와 같다.
구글 번역기는 웹에서 번역 콘텐츠를 긁어와서 학습한다.
인간의 개입이나 도움 없이 수많은 데이터를 바탕으로 스스로 어떻게 번역 됐는지 이해한다.
기존 통계적 번역과 달리 기계 번역은 문장 단위로 번역해 문맥을 활용해 적합한 번역을 파악하는 방식으로 번역을 한다.
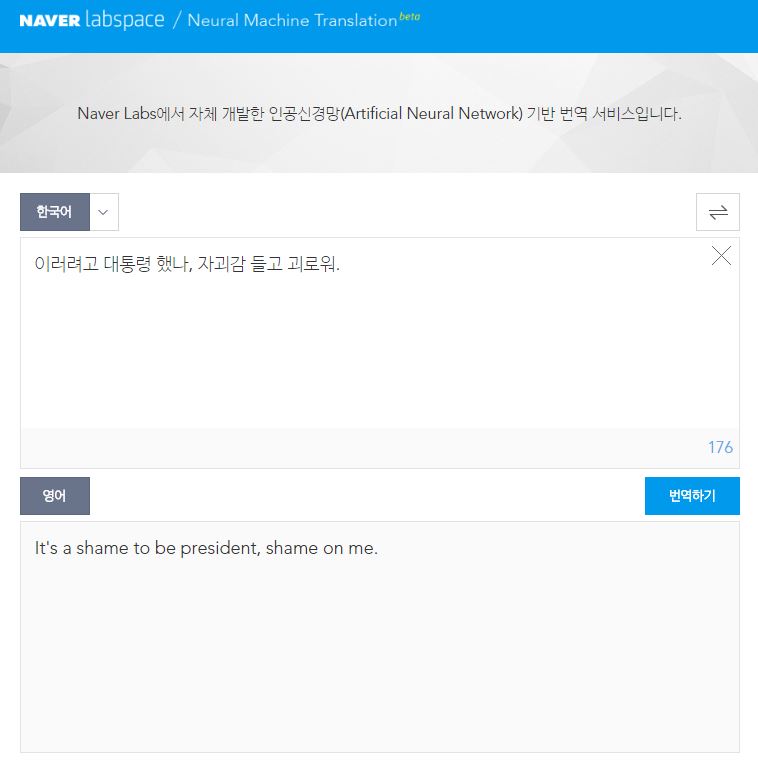
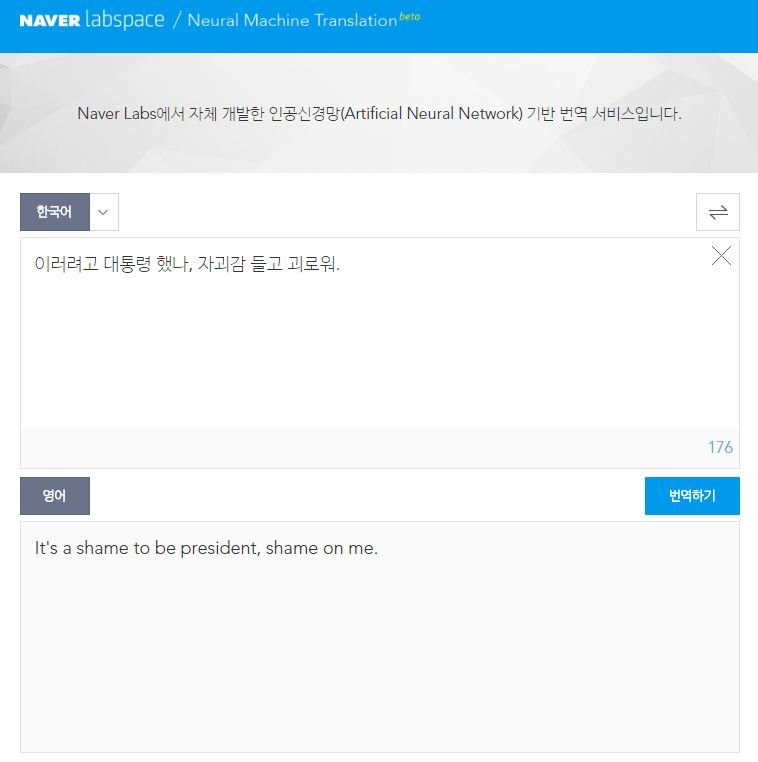
구글 번역기에 사용된 기술이 ‘신경망 기계번역’ 기술은 네이버도 사용하고 있는 기술이다.
구글은 GNMT (Google Neural Machine Translation), 네이버는 N2MT (Naver Neural Machine Translation)이라고 부른다.
#2 한국어·일본어·터키어는 한데 묶여 학습됐다
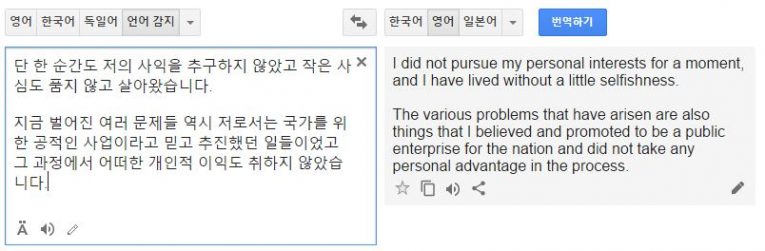
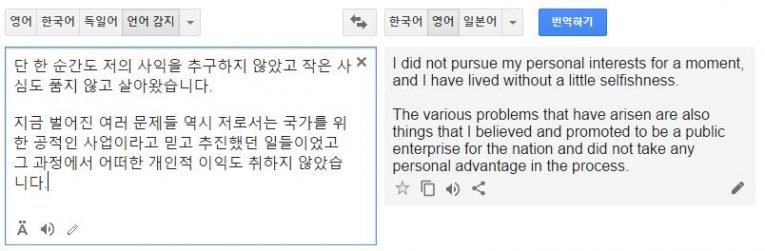
구글 신경망 기계번역 기술이 적용된 언어는 한국어, 영어, 프랑스어, 독일어, 스페인어, 포르투갈어, 중국어, 일본어, 터키어 등 9개의 언어 조합이다.
신경망 기계 번역 기술은 다중 언어를 한 번에 학습 시킬 수 있어 특성이 비슷한 언어는 한 번에 묶여 학습된다.
한국어와 일본어, 터키어는 언어적 특성이 유사해 함께 훈련됐다.
#3 데이터가 부족한 언어의 학습도 가능하다
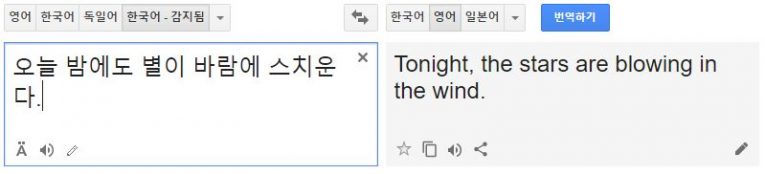
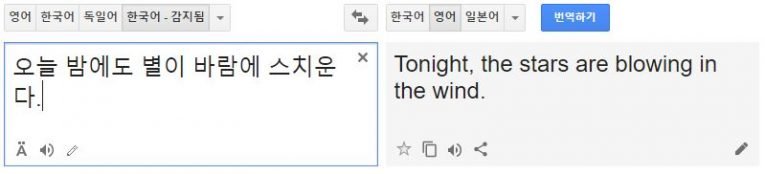
언어와 언어 사이의 번역 데이터가 부족해도 언어의 학습이 가능하다.
한국어 – 영어, 일본어 -영어의 번역 데이터가 각각 많고 한국어 – 일본어의 번역 데이터의 수가 적다면 한국어 – 영어 – 일본어를 함께 넣어 기계를 훈련시킬 수 있다.
또한 인터넷에서 잘 사용되지 않거나 공개되지 않은 언어의 학습도 가능하다.
힌디어 계열의 방언이라면 힌디어 데이터를 활용해 기계에 번역을 학습시킬 수 있다.
#4 편견이 반영된 경우도 있다
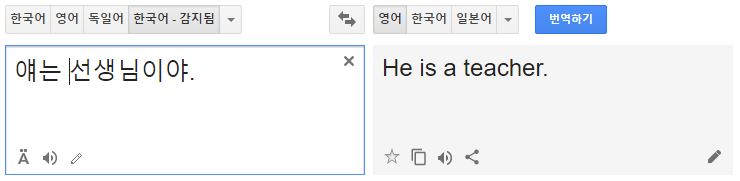
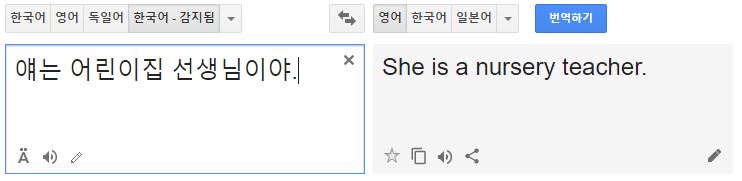
성별을 특정하지 않는 대명사를 번역할 때 편견이 반영된 결과물이 나오기도 한다.
‘어린이집 선생님’일 때는 주어를 여성형으로 사용하고, ‘선생님’은 주어를 남성형으로 사용하는 식이다.
버락 투로프스키 총괄은 “기계 번역이 가지고 있는 가장 흔한 문제로, 훈련 데이터만을 사용할 때의 어려움이 있다”고 밝혔다.
#5 신조어도 번역할 수 있다
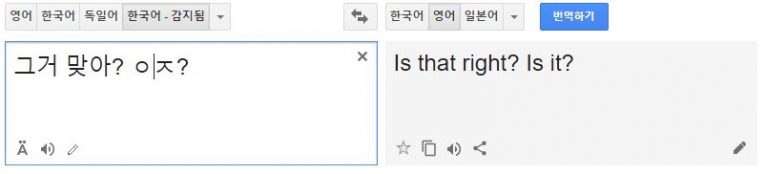
인터넷 공간에서 만들어진 신조어도 번역이 가능하다.
예컨대 ‘ㅇㅈ?'(인정하니?)의 경우 ‘Is it?’으로 번역이 된다.
인터넷에서 쓰이는 ‘야민정음’도 번역이 가능하다.
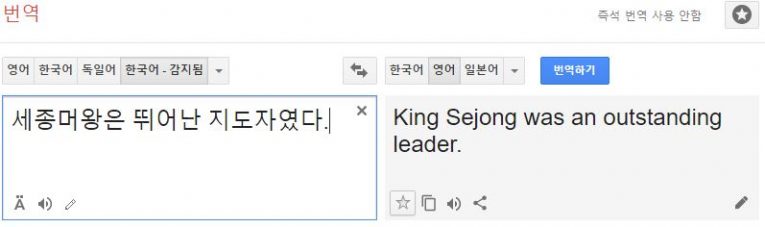
야민정음은 모양이 비슷한 글자를 대체하는 표기법이다.
예를 들어 박근혜의 경우 ‘박ㄹ혜’로, 세종대왕의 경우 ‘세종머왕’, 멍멍이는 ‘댕댕이’로 표시하는 표기법이다.
새로운 번역의 기준이 문장이기 때문에 제대로 모양이 갖춰져 있지 않은 단어도 비교적 적절한 번역이 가능하다.